
티스토리 뷰
1. 대량 데이터발생에 따른 테이블 분할 개요
- 차선이 넓은 도로에서 정체현상?
** 테이블 분할 설계를 통한 성능 저하의 예방
1) 수평분할 : 컬럼 단위로 분할하여 I/O(Input/Output) 경감
2) 수직분할 : 로우 단위로 분할하여 I/O 경감

** 성능저하의 원인
1) 하나의 테이블에 데이터 대량집중 : 한 테이블에 데이터가 대량으로 집중될때 테이블 구조가 너무 커져서 효율성이 떨어져 테이버를 처리할 때 디스크 I/O를 많이 유발하게 된다.
2) 하나의 테이블에 여러개의 컬럼 존재 : 이 경우 디스크의 점유량이 높아지고 데이터를 읽는 I/O량이 많아져서 성능이 저하된다.
3) 대량의 데이터가 처리되는 테이블의 경우 : SQL문장에서 데이터를 처리하기 위한 I/O의 양이 증가한다. 인덱스를 적절하게 구성하여 이용하면 이를 줄일 수 있다.
4) 대량의 데이터가 하나의 테이블에 존재할때 : 인덱스를 생성할 때 인덱스의 크기(용량)가 커지게 되고 그렇게 되면 인덱스를 찾아가는 단계가 깊어지게 되어 조회의 성능에도 영향을 미치게 됨 참고) 인덱스가 커지면?
- select -> ok
- insert/update/delete -> 성능저하
5) 컬럼이 많아지는 경우 : 물리적인 디스크에 여러 블록에 데이터가 저장되게 된다.
- 로우 체이닝 (Row chaining) : 로우 길이가 너무 길어서 블록 한에 데이터가 모두 저장되지 않고 두개 이상의 블록에 걸쳐 하나의 로우가 저장되어 있는 형태
- 로우 마이그레이션(Row Migration) : 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식 -> 두 가지 모두 불필요한 I/O가 많이 발생하여 성능이 저하된다.
2. 한 테이블에 많은 수의 컬럼을 가지고 있는 경우


** 컬럼수가 적은 테이블에서 데이터를 처리하게 되면 디스크의 I/O양이 감소하여 성능이 향상됨
3. 대량 데이터 저장 및 처리로 인해 성능이 저하되는 경우
해결책?
- 파티셔닝
- PK에 의한 테이블 분할
* 보통 데이터량이 천만건을 넘어서면 아무리 서버사양이 좋고, 인덱스를 잘 생성해 준다고 하더라도 SQL문장의 성능이 나오지 않는다.
-> 논리적으로는 하나의 테이블로 보이지만 물리적으로는 여러개의 테이블 스페이스에 쪼개어 저장될 수 있는 구조의 파티셔닝을 적용해야 한다.
** 파티셔닝
1) Range Partition
* 가장 많이 사용됨
- 적용대상 : 대상 테이블이 날짜 or 숫자값으로 분리가 가능하고, 각 영역별로 트랜잭션이 분리
- 장점 : 데이터 보관주기에 따라 테이블에 데이터를 쉽게 지우는 것이 가능함

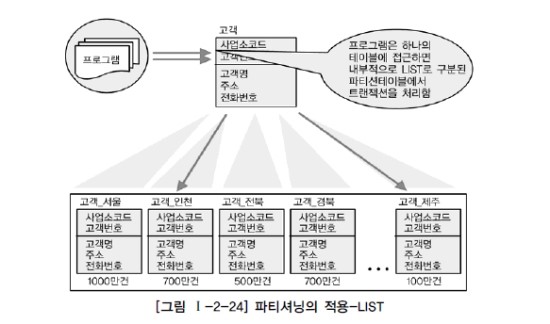
2) List Partition
- 장점 : 대용량 데이터를 특정값에 따라 분리/저장 가능
- 단점 : 쉽게 삭제되는 기능은 없다.
3) Hash partition
- 저장된 해쉬 조건에 따라 해슁 알고리즘이 적용되어 테이블이 분리된다. 데이터의 확인이 어렵고 삭제가 불가능.
4. 테이블에 대한 수평분할/수직분할의 절차
* 4가지 원칙
1) 테이터 모델링을 완성한다.
2) 데이터 베이스 용량선정을 한다. -> 컬럼수가 많은가?
3) 대량 데이터가 처리되는 테이블에 대해서 트랜잭션 처리 패턴을 분석한다.
4) 컬럼 단위로 집중화된 처리가 발생하는지, 로우 단위로 집중화된 처리가 발생하는지 분석하여 집중화된 단위로 테이블을 분리하는 것을 검토한다.
- 컬럼수가 많으면? -> 1:1로 분리 가능한지 검토한다.
- 컬럼수는 적으나 데이터 량이 많다면? -> 파티셔닝 고려한다.
[출처] http://www.bysql.net
- Total
- Today
- Yesterday
- 블로킹
- 인터셉터
- Synchronous
- 프로그래머스 Level 3
- Asynchronous
- Handler Interceptor
- blocking
- 해시
- 논블로킹
- 프로그래머스 Level 2
- 프로그래머스 Level 1
- 비동기
- 필터
- 코딩테스트 고득점 Kit
- 스택/큐
- http://www.nextree.co.kr/p6960/
- non-blocking
- 핸들러 인터셉터
- 동기
- Filter
- a
- 프로그래머스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |